mvSQLite is the open-source, SQLite-compatible distributed database built on FoundationDB. You might be interested in the introduction post if this is the first time you heard of mvSQLite.
This post explains how multi-versioned data is stored and how externally-consistent ACID transactions work in mvSQLite.
Preface
mvSQLite's storage layer is designed around two core ideas: immutability and concurrency.
Immutable versions and branching are well-known concepts in Git-based modern software workflows, and mvSQLite brings these to the database world. mvSQLite keeps all historic versions of the database accessible. Different from traditional mechanisms for implementing Point-in-Time Recovery (PITR), mvSQLite does not checkout a historic version by replaying the logs - instead, the time complexity of reading from a time in the past is O(log n), identical to that of reading the current version.
Concurrency is a core property users expect from distributed databases. Uniquely in the distributed SQLite world, mvSQLite provides both read and write concurrency across a cluster of machines: readers do not conflict with each other, readers do not conflict with writers, and multiple writers sometimes conflict with each other.
In the rest of this post I will explain how mvSQLite implements immutability and concurrency.
Layered page index
Vanilla SQLite stores data in a single file on the local disk. From the perspective of SQLite's virtual filesystem (VFS), the minimal unit of data is a page - a byte sequence with a fixed length ranging from 512 to 65536 bytes.
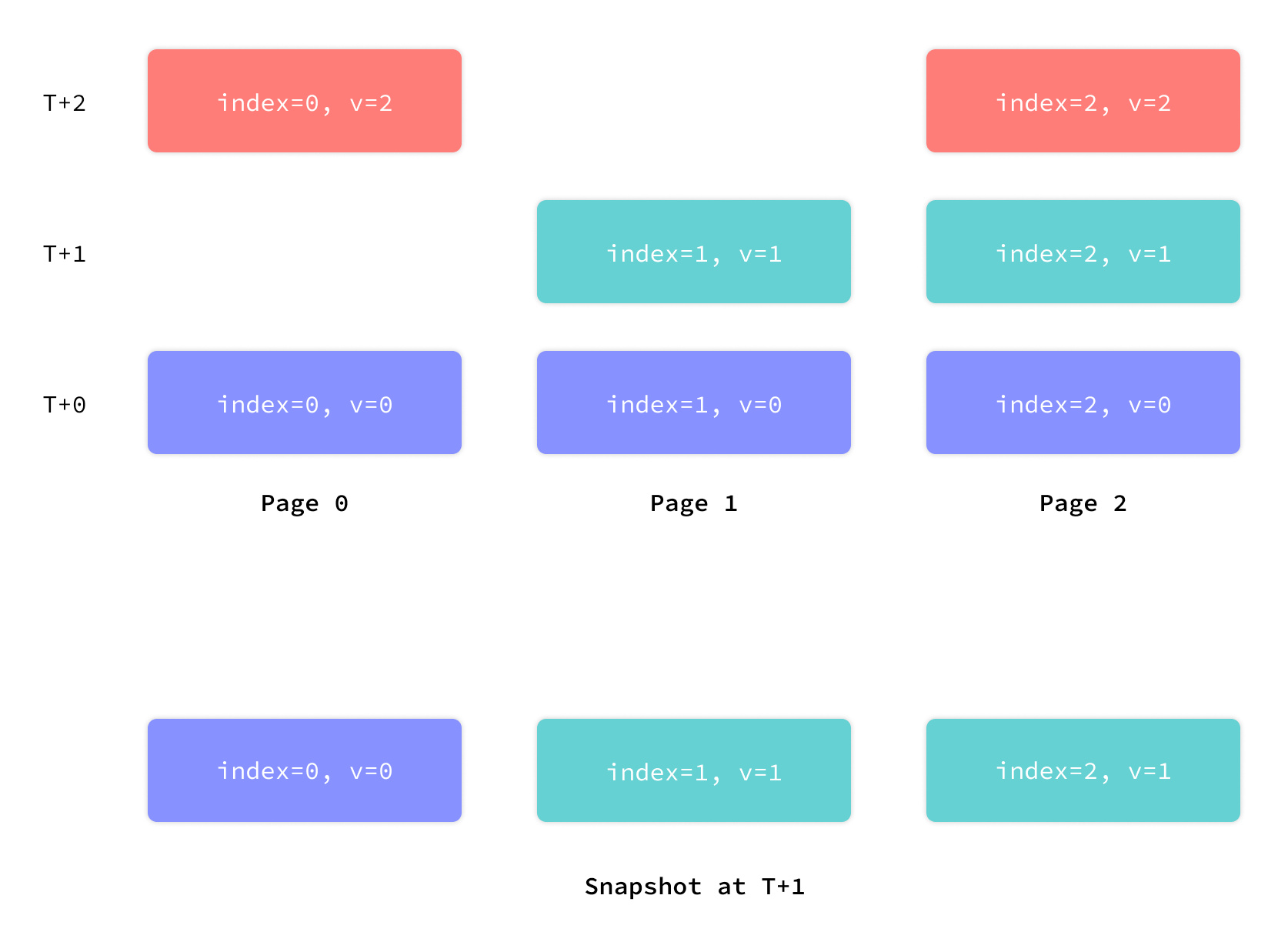
mvSQLite maps the concept of pages to FoundationDB as a set of (page_number, page_versionstamp) -> page_hash key-value mappings. When a page is requested by a client, the storage layer performs a reverse range scan on the key range (page_number, 0)..=(page_number, requested_versionstamp) with limit=1 to find out the latest versionstamp that satisfies the client version constraint. At any given versionstamp, the collection of all pages as observed by the above logic forms a consistent snapshot of the database.
Here's an illustration of the mechanism.
What is a versionstamp?
The concept "versionstamp" is used in this section. It's the "timestamp" handed out by FoundationDB's logical clock: a monotonic 80-bit integer, uniquely assigned to each FDB transaction during commit.
The order between two versionstamps is equivalent to the logical order between the corresponding FDB transactions. If versionstamp(A) < versionstamp(B), then transaction A logically happens before transaction B.
The content-addressed page store
The content-addressed page store is a set of page_hash -> page_content key-value mappings. On a client page read request, the storage layer looks up the hash in the store after fetching it from the layered page index.
Page content is not directly stored in the layered page index, because the index is designed to be compact. Compactness makes batch index operations efficient. These operations include transaction commit, which atomically writes a set of new page versions to the index, and garbage collection, which scans through the entire page index as part of the process for discovering garbage.
Delta encoding
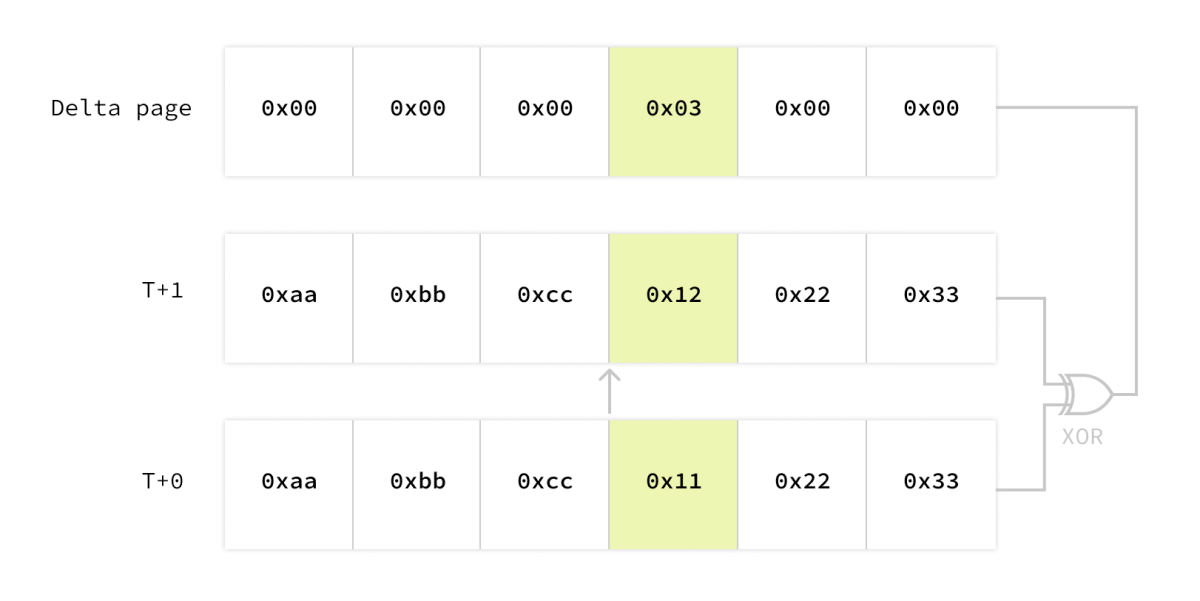
Page-level multi-versioning is useful to the external world, but introduces space efficiency challenges internally. One of these issues is that, what data should be stored when a page is changed? A naive implementation is to just store the entire page, but it is pretty wasteful: if you updated one row in a transaction, maybe only a single byte in a page is changed, but still the entire 8KiB is stored again.
So here's the delta page mechanism. Instead of storing the whole new version of the page, you only store the difference between the new and old versions. The difference is encoded by computing the XOR of the two versions, and then running zstd compression on the result. This gives us pretty efficient delta encoding.
Transacting on the page index
mvSQLite exposes the strictest transaction consistency level, aka external consistency, to applications. SQLite's default SERIALIZABLE isolation level applies, and linearizability is provided in addition.
Different from vanilla SQLite and most other replicated/distributed SQLite variants, mvSQLite does not rely on SQLite's own rollback journal or write-ahead log (WAL) to ensure transaction properties because FoundationDB provides more efficient primitives.
Let's see the lifetime of a transaction.
Phase 1: Initialization
When the first query after a BEGIN statement is executed, or one of BEGIN IMMEDIATE or BEGIN EXCLUSIVE is executed, the xLock VFS method is called and the client initializes the transaction.
Two pieces of metadata are fetched from the storage layer:
- Database read version.
- Mutation log since the client's last known version.
Page numbers included in the mutation log are flushed from the local in-memory cache.
Phase 2: Normal operation
VFS read requests are converted into storage layer page reads with the database read version fetched in Phase 1. VFS write requests are converted into content-addressed page store writes, and the hashes of newly written pages are kept in a in-memory buffer.
The page numbers from the VFS read requests are buffered in memory. This buffer is called the read set.
Phase 3: Commit
When the xUnlock VFS method is called, we know SQLite has decided to end the transaction. Rollback and commit don't really make a difference here, since on the page level a rollback is just a write-back of the original pages.
The client then sends the read version, the read set and the local mutations (page_number -> page_hash) to the storage layer, and requests for commit. Now the storage layer carefully performs a complex sequence of read-write conflict check, and then writes to the page index. Details of the commit logic is described in the Atomic commit documentation.
After the commit finishes, the storage layer returns a mutation log between the transaction's read version and the committed version, excluding the transaction's own mutations. Page numbers included in the mutation log are flushed from the local in-memory cache. This ensures we will not see stale data after concurrent mutations.
Try it
mvSQLite is beta software and is definitely not bug-free, but you can safely try it even for your important data as long as you have enabled FoundationDB's continuous backup system.
Refer to the readme for a guide on getting mvSQLite up and running!